La prise en charge d'Unicode dans EMu affecte la requête, et il est nécessaire d’échapper certains caractères spéciaux de requête, les caractères génériques par exemple. Pour échapper un caractère, il qu’il soit précédé d'un antislash (\). Ainsi, pour trouver tous les mots commençant par les lettres fre, nous cherchons fre\*.
Il n’est toutefois PAS nécessaire d'échapper les caractères génériques dans un Remplacer tout.
Note: Pour une étude détaillée de la prise en charge d’Unicode par EMu, consultez Prise en charge d’Unicode.
Plusieurs caractères génériques peuvent être inclus dans le champ Texte à trouver de Remplacer Tout :

Pour utiliser des caractères génériques :
- Placer le curseur à l'endroit du champ Texte à trouver où vous avez besoin d'un caractère générique.
- Sélectionner la case Expression régulière (en la cochant).
- Cliquez sur Caractères génériques....
Une liste de caractères génériques s'affiche :
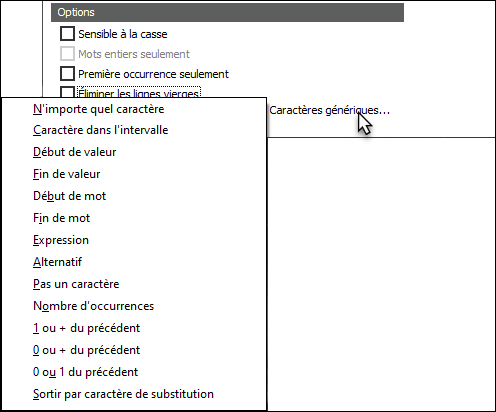
- Sélectionner une ou plusieurs expressions dans la liste.
Des caractères de repérage spéciaux sont ajoutés à la boîte Texte à trouver. Certains, comme Caractère dans l'intervalle, nécessitent que vous éditiez l'expression et spécifiiez les caractères.
Tip: Si vous saisissez ces caractères génériques dans le champ Texte à trouver plutôt que de les sélectionner dans la liste des caractères génériques, veillez à cocher la case Expression régulière en cliquant dessus.
Le tableau suivant décrit les caractères génériques :
|
Caractère générique |
Nom |
Description |
|---|---|---|
|
|
N'importe quel caractère |
Se rapporte à tout caractère unique à ce stade dans le champ Texte à trouver. Par exemple, localiser
et remplacer par
changera un champ contenant :
en :
|
|
|
Caractère dans l'intervalle |
Se rapporte à un des caractères compris à ce stade dans le Texte à trouver. Cela peut être une intervalle (signifié par un trait d'union) ou des caractères spécifiques (sans le trait d'union). Par exemple :
se rapporte à : cat et cot
|
|
|
Début de valeur |
Se rapporte à une valeur au début du champ (pas à l'intérieur du champ). Par exemple, pour localiser la lettre
Tip: ^ peut être combiné avec $ pour localiser les champs vides ; et pour localiser et remplacer le contenu entier d'un champ. Voir Utilisations de ^$ ci-dessous. |
|
|
Fin de valeur |
Se rapporte à une valeur à la fin du champ. Comme pour Début de valeur. Tip: ^ peut être combiné avec $ pour localiser les champs vides ; et pour localiser et remplacer le contenu entier d'un champ. Voir Utilisations de ^$ ci-dessous. |
^$
Saisissez Note: ^Texte à trouver$ Saisir le texte à trouver entre ^ (qui indique le début du champ) et $ (qui marque la fin du champ) indique que nous recherchons (et remplaçons) sur le contenu entier du champ. |
||
|
|
Début de mot |
Se rapporte à du texte en début de mot. Par exemple, localiser [[:<:]]nu et remplacer par be changera un champ contenant : Une option utile si votre orthographe est nulle en : Une option utile si votre orthographe est belle |
|
|
Fin de mot |
Se rapporte à du texte en fin de mot. Comme pour Début de mot. |
|
|
Expression |
Une expression est utilisée pour rassembler un ensemble de caractères afin d'appliquer le même caractère générique au groupe. Par exemple, un champ contient :
Pour localiser les occurrences où abc apparaît deux fois et le remplacer par cba :
|
|
|
Alternatif |
À utiliser quand plus d'un caractère alternatif compose une partie de la recherche. Par exemple : p(or|in)te se rapporte à : porte ou pinte |
|
|
Pas un caractère |
Spécifie qu'un caractère ne doit pas faire partie de la recherche. Par exemple : c[^ao]t localisera et remplacera cut mais pas cat ni cot. |
|
|
Nombre d'occurrences |
Spécifie le nombre de fois qu'une lettre est répétée dans le terme de la recherche. Par exemple, un champ contient :
Pour localiser les occurrences où C se répète entre 2 et 5 fois et le remplacer par x :
|
|
|
1 ou + du précédent |
Se rapporte à une ou plusieurs occurrences du caractère précédent. Par exemple, un champ contient : ab abc, abcc, abccc, abcccc Pour localiser les occurrences où C apparaît une fois ou plus et le remplacer par d :
|
|
|
0 ou + du précédent |
Se rapporte à zéro ou plus occurrences du caractère précédent. Par exemple, un champ contient : ab abc, abcc, abccc, abcccc Pour localiser les occurrences où c apparaît ou pas en combinaison avec ab et remplacer cela par x :
|
|
|
0 ou 1 du précédent |
Se rapporte à zéro ou une occurrence du caractère précédent. Par exemple, localiser : abc? et le remplacer par : x changera un champ contenant : ab abc, abcc en : x x xc |
|
|
Sortir par caractère de substitution |
Le caractère générique de substitution supprime toute signification particulière associée à un caractère, par exemple, abc\? se rapporte à abc? plutôt qu'à ab ou abc. |
Note: Des exemples de l'utilisation des caractères de remplacement dans un environnement multilingue sont disponibles ici. Ces exemples peuvent être utiles pour comprendre le fonctionnement de Remplacer tout.

